Breast Cancer Prediction
Machine Learning Project
Supported Vector Machine Model
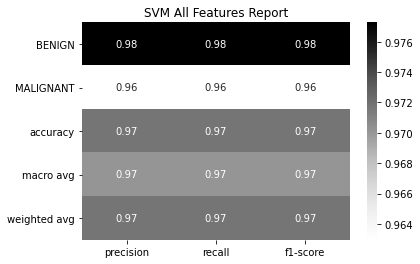
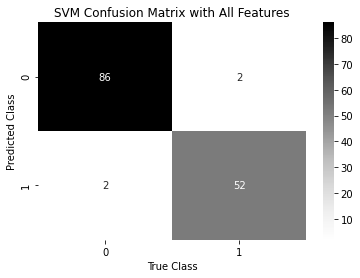
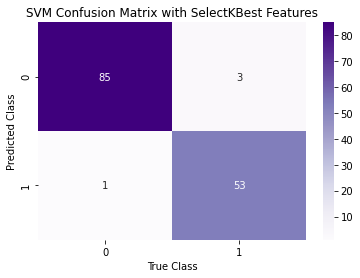
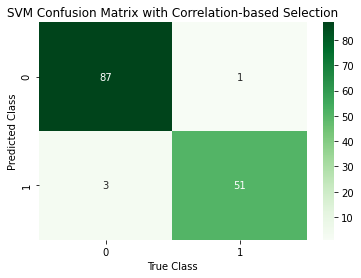
Support vector classifier is a classifier model for the support vector machine. Support Vector Machine (SVM) is a supervised machine learning algorithm which can be used for both classification or regression challenges. A Support Vector Machine (SVM) is a discriminative classifier formally defined by a separating hyperplane. In other words, given labelled training data (supervised learning), the algorithm outputs an optimal hyperplane which categorizes new examples. In two-dimensional space this hyperplane is a line dividing a plane in two parts where in each class lay in either side. Each Graph is representing you accuracy & confusion matrix of different feature selection. First one is for all 30 features. second one is for selected 7 best features which has high impact on this dataset. Last one is based on features selected based on correlation.
Step 1: Load the data
Step 2: First, it finds decision boundaries that correctly classify the training dataset.
Step 3: Pick the decision boundary which has maximum distance from the nearest points (supported vectors) of these two classes as the best one.
Step 4: Predict values using the SVM algorithm model
Step 5:Calculate the accuracy and laid out confusion matrix
SVM Model with Full 30 Features
SVM Model with 7 BestFeature Selected Features
SVM Model with 7 Correlation Selected Features
Observations:
1. Model accuracy only declined slightly after reducing feature number from 30 to 7.
2. Although accuracy for both 7 feature models were the same, the model with 7 BestFeature selected features was better at predicting Benign while the model with 7 correlation selected features was better at predicting Malignant.